| 完成一次读/写的过程 | CPU干预频率 | 每次I/O的数据传输单位 | 数据流向 | 优缺点 |
| 程序直接控制方式 | CPU发出I/O命令后需要不断轮询 | 极高 | 字 | 设备→CPU→内存
内存→CPU→设备 | 每一个阶段的优点都是解决了上一阶段的最大缺点。总体来说,整个发展过程就是要尽量减少CPU对I/O过程的干预,把CPU从繁杂的I/O控制事务中解脱出来,以便更多地去完成数据处理任务。 |
| 中断驱动方式 | CPU发出I/O命令后可以做其他事,本次I/O完成后设备控制器发出中断信号 | 高 | 字 | 设备→CPU→内存
内存→CPU→设备 |
| DMA方式 | CPU发出I/O命令后可以做其他事,本次I/O完成后DMA控制器发出中断信号 | 中 | 块 | 设备→内存
内存→设备 |
| 通道控制方式 | CPU发出I/O命令后可以做其他事。通道会执行通道程序以完成I/O,完成后通道向CPU发出中断信号 | 低 | 一组块 | 设备→内存
内存→设备 |
# 磁盘调度算法
# FCFS
根循进程请求访问磁盈的光后顺序进仃调度。
假设磁头的初始位置是100号磁道,有多个进程先后陆续地请求访间55、58、39、18、90、160、
150、38、184号磁道
按照FCFS的规则,按照请求到达的顺序,磁头需要依次移动到55、58、39、18、90、160、150、
38、184号磁道
磁头总共移动了45+3+19+21+72+70+10+112+146=498个磁道
响应一个请求平均需要移动498/9=55.3个磁道(平均寻找长度)
优点:公平:如果请求访问的磁道比较集中的话,算法性能还算过的去
缺点:如果有大量进程竞争使用磁盘,请求访问的磁道很分散,则FCFS在性能上很差,寻道时间长。
SSTF算法会优先处理的磁道是与当前磁头最近的磁道。可以保证每次的寻道时间最短,但是并不能保证总的寻道时间最短。(其实就是贪心算法的思想,只是选择眼前最优,但是总体未必最优)
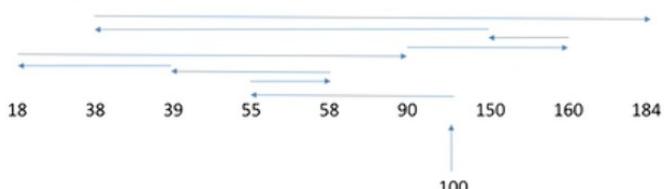
假设磁头的初始位置是100号磁道,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(100-18)+(184-18)=248个磁道
响应一个请求平均需要移动248/9=27.5个磁道(平均寻找长度)
优点:性能较好,平均寻道时间短
缺点:可能产生“饥饿”现象
Eg:本例中,如果在处理18号磁道的访问请求时又来了一个38号磁道的访问请求,处理38号磁道的访问请求时又来了一个18号磁道的访问请求。如果有源源不断的18号、38号磁道的访问请求
到来的话,150、160、184号磁道的访问请求就永远得不到满足,从而产生“饥饿”现象。
SCAN
SSTF算法会产生饥饿的原因在于:磁头有可能在一个小区域内来回来去地移动。为了防止这个问题,可以规定,之哦有磁头移动到最外侧磁道的时候才能往内移动,移动到最内侧磁道的时候才能往外移动。这就是SCAN的思想。
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(200-100)+(200-18)=282个磁道
响应一个请求平均需要移动282/9=31.3个磁道(平均寻找长度)
缺点:①只有到达最边上的磁道时才能改变磁头移动方向,事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。
②SCAN算法对于各个位置磁道的响应频率不平均(如:假设此时磁头正在往右移动,且刚处理过90号磁道,那么下次处理90号磁道的请求就需要等磁头移动很长一段距离:而响应了184号磁道的请求之后,很快又可以再次响应184磁道的请求。
# 注意接下来的LOOK调度算法才是教材里的SCAN算法
扫描算法(SCAN)中,只有到达最边上的磁道时才能改变磁头移动方向,事实上,处理了184号磁道的访问请求之后就不需要再往右移动磁头了。LOOK调度算法就是为了解决这个问题,如果在磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向(边移动边观察,因此叫LOOK)
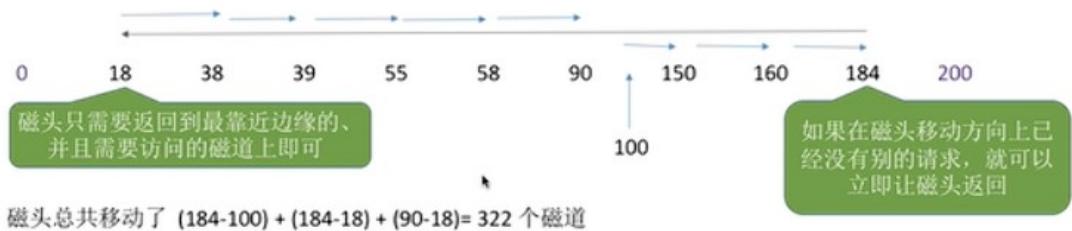
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

磁头总共移动了(184-100)+(184-18)=250个磁道
响应一个请求平均需要移动 $2 5 0 / 9 = 2 7 . 5$ 个磁道(平均寻找长度)
优点:比起SCAN算法来,不需要每次都移动到最外侧或最内侧才改变磁头方向,使寻道时间进
# CSCAN 算法
SCAN算法对于各个位置磁道的响应频率不平均,而C-SCAN算法就是为了解决这个问题。规定只有磁头朝某个特定方向移动时才处理磁道访问请求,而返回时直接快速移动至起事端而不处理任何请求。
假设某磁盘的磁道为0~200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大移动,有多个进程先后陆续地请求访问55、58、39、18、90、160、150、38、184号磁道

只有到了最边上的磁道才能改变磁头移动方向,磁头返回途中不处理任何请求。
磁头总共移动了(200-100)+(200-0)+(90-0)=390个磁道
响应一个请求平均需要移动390/9=43.3个磁道(平均寻找长度)
优点:比起SCAN来,对于各个位置磁道的响应频率很平均。
注意接下来的C-LOOK调度算法才是我们教材中的的CSCAN算法
C-SCAN算法的主要缺点是只有到达最边上的磁道时才能改变磁头移动方向,并且磁头返回时不一定需要返回到最边缘的磁道上。C-LOOK算法就是为了解决这个问题。如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
假设某磁盘的磁道为0-200号,磁头的初始位置是100号磁道,且此时磁头正在往磁道号增大的方向
移动,有多个进程先后陆续地请求访间55、58、39、18、90、160、150、38、184号磁道
假脱机技术:用ru
脱离主机的控制进行的输入/输出操作
在磁盘上开辟两个存储区域——输入井和输出井
外围控制机
假脱机技术,又称“SPOOLing”技术,用软件的方式模拟脱机技术。SPOOLing系统
"输入进程"模拟脱机输入时的外围控制机。
“输出进程“模拟脱机输出时的外围控制机。

输入井和输出井
内存中输入缓冲区、输入进程
输出缓冲区、输出进程

当多个用户进程提出输出打印的请求时,系统会答应它们的请求,但是并不是真正把打印机分配给他们,而是由假脱机管理进程为每个进程做两件事:
(1)在磁盘输出井中为进程申请一个空闲缓冲区(也就是说,这个缓冲区是在磁盘上的),并将要打印的数据送入其中:
(2)为用户进程申请一张空白的打印请求表,并将用户的打印请求填入表中(其实就是用来说明用户的打印数据存放位置等信息的),再将该表挂到假脱机文件队列上。
当打印机空闲时,输出进程会从文件队列的队头取出一张打印请求表,并根据表中的要求将要打印的数据从输出井传送到输出缓冲区,再输出到打印机进行打印。用这种方式可依次处理完全部的打印任务
杂项:
面对一般用户,通过操作命令控制操作系统
面对编程人员,通过系统调用控制
作业的输入方式有:联机输入,脱机输入,直接耦合,假脱机,网络输入