| 约束操作 | 说明 |
| RESTRICT (拒绝) | 默认行为,阻止删除或修改父表记录(如果子表有引用)。 |
| NO ACTION | 类似于 RESTRICT,但某些数据库(如 PostgreSQL)会在事务结束时检查。 |
| CASCADE (级联) | 父表记录被删除或更新时,自动删除或更新子表对应的记录。 |
| SET NULL (置空) | 父表记录被删除或更新时,子表的外键列设为 NULL(要求外键列允许NULL)。 |
| SET DEFAULT | 父表记录被删除或更新时,子表的外键列设为默认值(需定义 DEFAULT T)。 |
# Check 约束:
$\star$ 约束条件可以是任何 Where 中出现的字句;
故具有很强的表述能力;
$\star$ 常用于数据的值域约束;
# 三、User Defined Integrity and Default、Check
# Eg.
1. sex char(2) check (sex IN (‘男’,‘女’)) default‘男 ’,
2. age int check (age>=16 and age $\mathtt { < } \mathtt { = } 7 0$ ),
# Eg.
1. sex char(2) check (sex IN (‘男’,‘女’)) default‘男 ’,
2. age int check (age>=16 and age $\mathtt { < } \mathtt { = } 7 0$ ),
# 触发器 Trigger
Create Table中的表约束和列约束基本上都是静态的约束,也基本上都是对单一列或单一元组的约束(尽管有参照完整性),为实现动态约束以及多个元组之间的完整性约束,就需要触发器技术 Trigger
Trigger是一种过程完整性约束(相⽐之下,Create Table中定义的都是非过程性约束),是一段 SQL 程序,该程序在对表或视图执行 UPDATE、INSERT 或 DELETE 操作时自动触发执行。
# 基本语法
# CREATETRIGGER
# trigger_name
# BEFORE | AFTER
```sql
{ INSERT | DELETE | UPDATE [OF colname {, colname...}] } ON tablename [REFERENCING corr_name_def {, corr_name_def...}] [FOR EACH ROW | FOR EACH STATEMENT]
```
//对更新操作的每一条结果(前者:行级触发器),或整个更新操作完成(后者:语句级触发器)
```objectivec
[WHEN (search_condition)] { statement
```
//检查条件,如满足执行下述程序
//单行程序直接书写,多行程序要用下行方式
```typescript
BEGIN ATOMIC statement; {statement;...} END }
```
```txt
> 触发器 Trigger 意义:当某一事件发生时(Before|After),对该事件产生的结果(或是每一元组,或是整个操作的所有元组),检查条件 search_condition,如果满足条件,则执行后面的程序段。条件或程序段中引用的变量可用 corr_name_def 来限定。
```
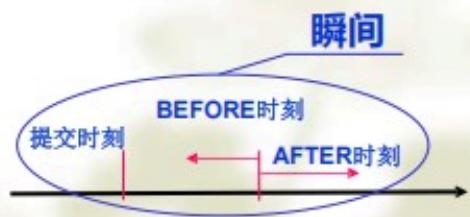
事件:BEFORE|AFTER{INSERT|DELETE| UPDATE..}
□当一个事件(Insert,Delete,或Update)发生之前Before或发生之后After触发
□DELETE/INSERT/UPDATE操作发生,执行触发器操作需处理两组值:更新前的值和更新后的值,这两个值由corr_name_def的使用来区分
□对于UPDATE触发器,每当UPDATE语句修改由OF子句指定的列值时,激发触发器;如果忽略OF子句,每当UDPATE语句修改表的任何列值时,DBMS都将激发触发器。
```sql
CREATE TRIGGER trigger_name BEFORE|AFTER
{INSERT|DELETE|UPDATE [OF colname{,colname...}]}
ON tablename [REFERENCING corr_name_def{,corr_name_def...}]
[FOR EACH ROW|FOR EACH STATEMENT]
//对更新操作的每一条结果(前者),或整个更新操作完成(后者)
[WHEN (search_condition)] //检查条件,如满足执行下述程序
{statement //单行程序直接书写,多行程序要用下行方式
|BEGIN ATOMIC statement; {statement,...} END}
```
属性上的约束条件:NOT NULL
UNIQUE
CHECK
表上的约束条件 CASCADDE NO ACTION RESTRICT
# 2.1 安全性
数据库的完整性是指尽可能避免对数据库的无意的滥用;
数据库的安全性是指尽可能避免对数据库的恶意的滥用。
数据库系统的安全措施是建立在计算机系统基础之上的,通常有五个方面。
(1) 用户标识和鉴定
(2) 存取控制
(3) 定义视图
(4) 审计
(5) 数据加密
用户或应用程序使用数据库的方式称为权限。
授权子系统可以保证用户只能进行其权限范围内的操作,并允许有特定权限的用户有选择地和动态地把这些权限授予其他用户。
(1)用户权限
(2)授权语句
GRANT <权限表> ON <数据库对象> TO <用户名> [WITH GRANT OPTION]
(3)回收权限
REVOKE <权限表> ON <数据库对象> FROM <用户名 $>$ [CASCADE]
用户与角色:它们之间的关系、权限的继承性、角色授权的高效和便捷性
会判断用户加入某个角色后的最终的权限是什么(自己被授予的权限加上继承了角色的权限,但要去掉被DENY掉的权限)(详见第四章安全性补充PPT)
视图是从一个或几个基本表导出的表,是虚表,视图定义后可以像基本表一样用于查询和删除, 但其更新操作(增、删、改)会受到限制。
视图机制把用户可以使用的数据定义在视图中,这样用户就不能使用视图定义外的其他数据,从而保证了数据库的安全性。
视图机制使系统具有三个优点:数据安全性、数据独立性和操作简便性。
事务是一个操作序列。 这些操作要么什么都做,要么都不做,是一个不可分割的工作单位
在应用程序 中 ,事务以 BEGIN TRANSACTION 语 句 开 始 , 以 COMMIT(提交)语 句 或ROLLBACK(回退或撤消)语句结束。 一个程序的执行可通过若干事务的执行序列来完成。事务是不能嵌套的,可恢复的操作必须在一个事务的界限内才能执行.
# 例1:
grant select on Student to public
例2:
grant all on Student to u2
# 例3:
grant update(Sno),select on Student 例4:
grant insert on SC to u5
with grant option
# 3.2 事务的性质
事务的ACID性质:
原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
3.3 故障类型和恢复方法