## 概要
是结构化的语义知识库,其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性值对。
实体(结点)通过关系(边)相互连结,构成网状的知识结构。
让Web不是按字符串而是按主题,实现真正的语义检索。
**本质上是基于图的神经网络,表示实体和实体之间的关系的语义网络。**
如果计算机能把My friends who live in Canada 理解成friends(me)和residents(id:12345,Canada)的交集,那么就真实了理解这个语义。
Photos of my friends who live in Canada
人和人、人和居住地、人和照片的交集
## 技术架构
### 表示方式
RDF
RDF定义了描述资源、属性和值之间的关系;资源可以用URI标识的所有事物,属性是一个特定方面或特征,值可以是另一个资源,字符串。
RDF描述就是一个三元组:<主语,谓语,宾语>
RDFs
在RDF数据层的基础上引入模式层、定义类、属性、关系、属性的定义域与值域来描述与约束资源,构建最基本的类层次体系和属性体系。支持简单的上下位推理。
本体语言OWL
可声明类间互斥关系、属性的传递性等复杂语义。支持基于本体的自动推理,提供了适合web传播的描述逻辑的语法。
三元组是知识图谱的一种通用表示方式,即$G=(E,R,S)$
$E = \{ e_1, e_2,...,e_{|E}|\}$,是知识库的实体集合,包含$|E|$中不同实体
$R=\{r_1,r_2,...,r_{R}\}$是知识库的关系集合,包含$|R|$种不同关系;
$S\subseteq E\times R\times E$代表知识库的三元组集合。
三元组的基本形式主要包括实体1、关系、实体2,和概念、属性、属性值。
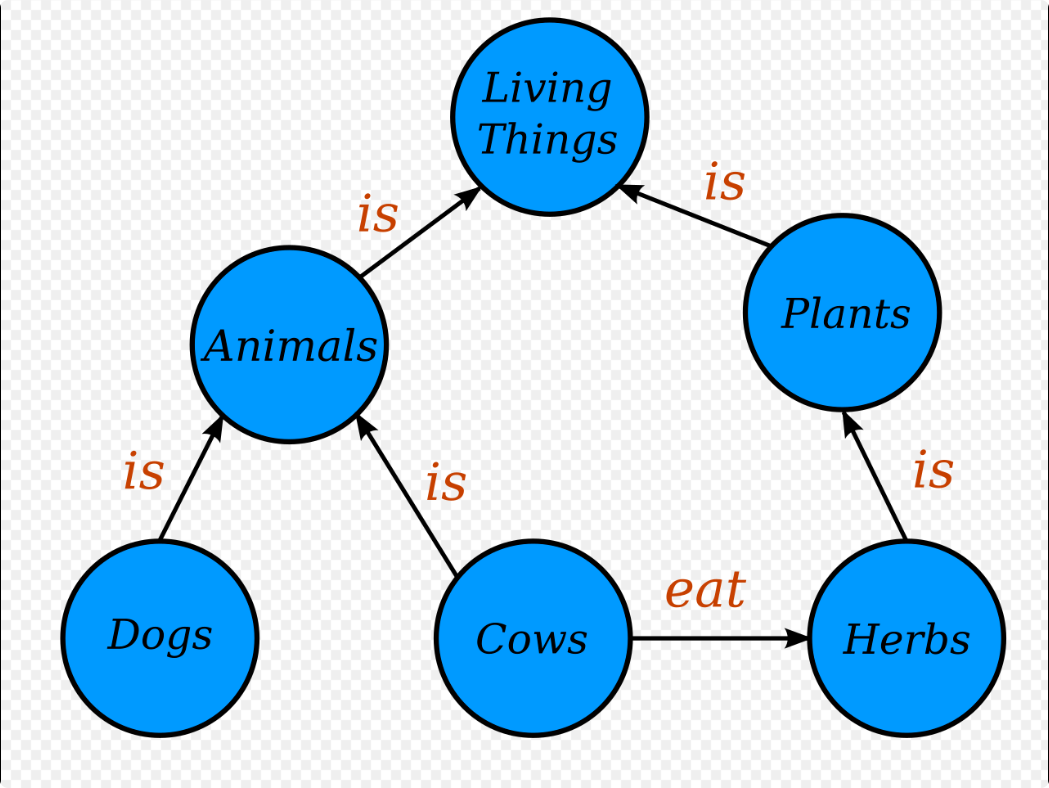
实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。
概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;
属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;
属性值主要指对象指定属性的值,例如中国、1988-09-08等。
每个实体(概念的外延)可用一个全局唯一确定的ID来标识,每个属性-属性值对(attribute-value pair, AVP) 可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
**对于概念、属性、属性值的理解**
“熊猫” 是图谱中的一个**节点(实体节点)**。
“食性” 是一条**边(属性关系)**。
“植食” 是一个**属性值节点(值节点)**,通常画成小方框或者椭圆,表示它不是一个可继续扩展的实体,而是一个具体的字面量(如字符串、数值、时间等)。
| 项目 | 实体-关系-实体 | 概念/实体-属性-属性值 |
| -------- | ------------------------ | ---------------------- |
| 例子 | (乔布斯, 创立, 苹果公司) | (乔布斯, 身高, 1.88米) |
| 尾部类型 | 实体(可扩展) | 字面量(不可扩展) |
| 图中形式 | 节点→边→节点 | 节点→边→值框 |
| 意义 | 两个事物的外部关系 | 一个事物的内部特征 |
| RDF 表示 | 对象是 URI | 对象是 Literal |
### 架构
#### 逻辑结构
知识图谱在逻辑架构上分为两个层次:数据层和模式层。
数据层是以事实(fact)为**存储单位的图数据库**,其事实的基础表达方式就是“实体-关系-实体”或者“实体-属性-属性值”。
模式层存储的是经过提炼的知识,借助本体库来规范实体、关系以及实体类型和属性等之间的关系。
#### 体系架构
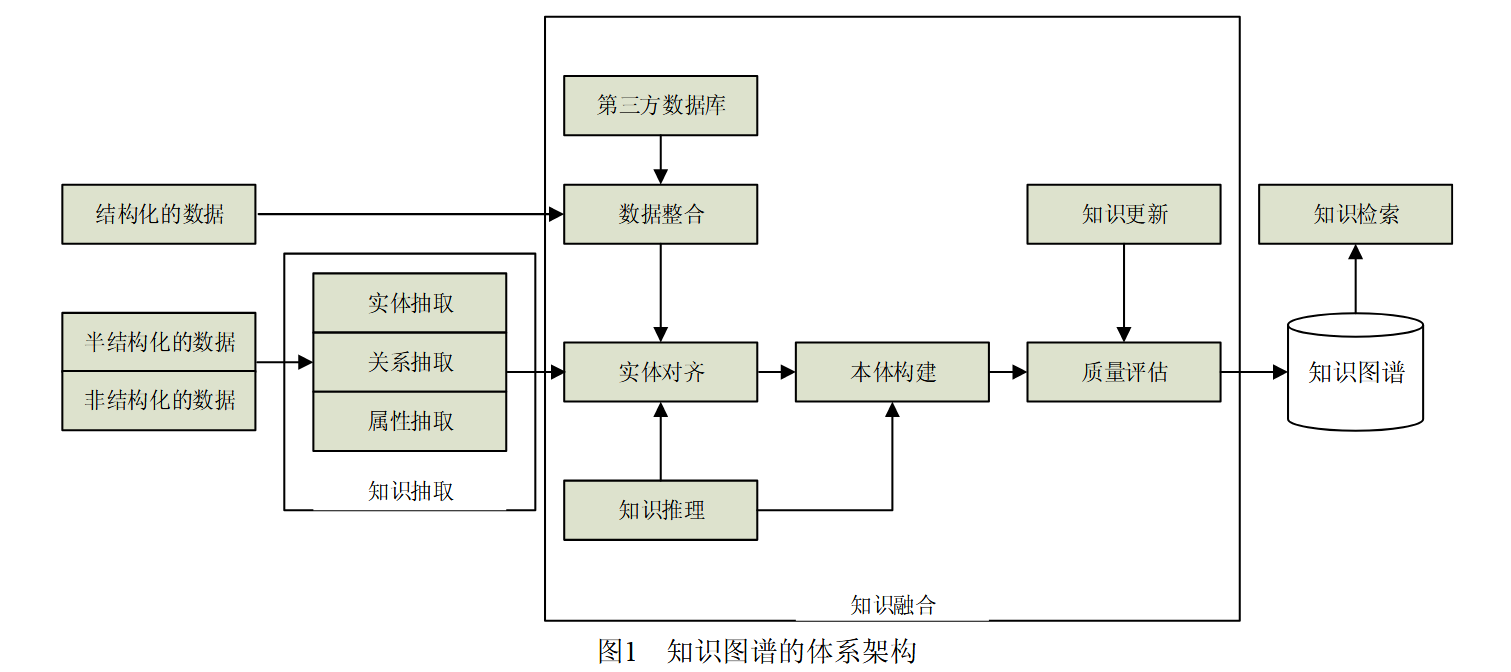
知识图谱的体系架构分为3个部分,分别获取源数据、知识融合和知识计算与知识应用。 知识图谱有两种构建方式,自顶向下和自底向上。
在知识图谱发展初期,知识图谱主要借助百科类网站等结构化数据源,先为 知识图谱定义好本体与数据模式,再将实体加入到 知识库。提取本体和模式信息,加入到知识库的自顶向下方式构建数据库。
现阶段知识图谱大多为公开采集数据并自动抽取资源,从一些开放链接数据中提取出 实体,选择其中置信度较高的加入到知识库,经过人工审核后加入到知识库中,这种则是自底向上的构建方式。

如果计算机能把My friends who live in Canada 理解成friends(me)和residents(id:12345,Canada)的交集,那么就真实了理解这个语义。
Photos of my friends who live in Canada
人和人、人和居住地、人和照片的交集
## 技术架构
### 表示方式
RDF
RDF定义了描述资源、属性和值之间的关系;资源可以用URI标识的所有事物,属性是一个特定方面或特征,值可以是另一个资源,字符串。
RDF描述就是一个三元组:<主语,谓语,宾语>
RDFs
在RDF数据层的基础上引入模式层、定义类、属性、关系、属性的定义域与值域来描述与约束资源,构建最基本的类层次体系和属性体系。支持简单的上下位推理。
本体语言OWL
可声明类间互斥关系、属性的传递性等复杂语义。支持基于本体的自动推理,提供了适合web传播的描述逻辑的语法。
三元组是知识图谱的一种通用表示方式,即$G=(E,R,S)$
$E = \{ e_1, e_2,...,e_{|E}|\}$,是知识库的实体集合,包含$|E|$中不同实体
$R=\{r_1,r_2,...,r_{R}\}$是知识库的关系集合,包含$|R|$种不同关系;
$S\subseteq E\times R\times E$代表知识库的三元组集合。
三元组的基本形式主要包括实体1、关系、实体2,和概念、属性、属性值。
实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。
概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;
属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;
属性值主要指对象指定属性的值,例如中国、1988-09-08等。
每个实体(概念的外延)可用一个全局唯一确定的ID来标识,每个属性-属性值对(attribute-value pair, AVP) 可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联。
**对于概念、属性、属性值的理解**
“熊猫” 是图谱中的一个**节点(实体节点)**。
“食性” 是一条**边(属性关系)**。
“植食” 是一个**属性值节点(值节点)**,通常画成小方框或者椭圆,表示它不是一个可继续扩展的实体,而是一个具体的字面量(如字符串、数值、时间等)。
| 项目 | 实体-关系-实体 | 概念/实体-属性-属性值 |
| -------- | ------------------------ | ---------------------- |
| 例子 | (乔布斯, 创立, 苹果公司) | (乔布斯, 身高, 1.88米) |
| 尾部类型 | 实体(可扩展) | 字面量(不可扩展) |
| 图中形式 | 节点→边→节点 | 节点→边→值框 |
| 意义 | 两个事物的外部关系 | 一个事物的内部特征 |
| RDF 表示 | 对象是 URI | 对象是 Literal |
### 架构
#### 逻辑结构
知识图谱在逻辑架构上分为两个层次:数据层和模式层。
数据层是以事实(fact)为**存储单位的图数据库**,其事实的基础表达方式就是“实体-关系-实体”或者“实体-属性-属性值”。
模式层存储的是经过提炼的知识,借助本体库来规范实体、关系以及实体类型和属性等之间的关系。
#### 体系架构
知识图谱的体系架构分为3个部分,分别获取源数据、知识融合和知识计算与知识应用。 知识图谱有两种构建方式,自顶向下和自底向上。
在知识图谱发展初期,知识图谱主要借助百科类网站等结构化数据源,先为 知识图谱定义好本体与数据模式,再将实体加入到 知识库。提取本体和模式信息,加入到知识库的自顶向下方式构建数据库。
现阶段知识图谱大多为公开采集数据并自动抽取资源,从一些开放链接数据中提取出 实体,选择其中置信度较高的加入到知识库,经过人工审核后加入到知识库中,这种则是自底向上的构建方式。
 ### 大规模知识库
1. 开放链接知识库
它们中不仅包含大量的半结构化、非结构 化数据,是知识图谱数据的重要来源。而且具有较 高的领域覆盖面,与领域知识库存在大量的链接关 系。
2. 垂直行业知识库
这类知识 库的描述目标是特定的行业领域,通常需要依靠特 定行业的数据才能构建,因此其描述范围极为有限。
## 关键技术
### 本体
计算机科学中,“本体”用于面对特定领域的形式化地对于共享概念体系的明确而又详细的说明。
是一种概念间的关系和相互间的规则。
比如“疾病”,在医学中的疾病本体,疾病中包含药物、科室、感染类疾病、传染类疾病
本体语言
DAML/W3C提出的DAML+OIL3以及知识图谱数据集常用W3C所定义的RDF(S)和OWL语言等。
工具
Protege和WebOnto
实体识别
实体消歧
关系抽取
事件抽取
### 知识抽取
知识抽取(information extraction)是构建知识图谱的第一步,为了从异构数据源中获取候选知识单元,知识抽取技术将自动从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息。
- 结构化数据
- 半结构化数据
- 非结构文本数据
一些长尾(long-tail)的数据就得要从文本数据
大规模知识抽取——全领域、开放领域,主要用于互联网公司的搜索引擎
Yago
DBPedia
Freebase:人们编辑结构化知识
**实体抽取**
实体抽取,也称为命名实体识别(named entity recognition,NER),指从源数据中自动识别命名实体,这一步是信息抽取中最基础和关键的部分,因为实体抽取的准确率和召回率对后续知识获取效率和质量影响很大。
- 基于规则与词典的方法:在有限的范围内,依靠大量专家编写规则,抽取信息
- 基于统计机器学习的方法:将机器学习中的监督学习算法用于抽取信息,单纯的监督学习性能、准确率都不够理想。
- 利用预先标注好的语料训练模型
最大熵膜学和条件随机模型。采用字典辅助下的最大熵算法,基于Medline论文摘要的GENIA数据集使得实体抽取的准召率均超过70%。
- 面向开放域的无监督学习算法,事先不给实体分类,而是基于实体的语义特征从搜索日志中识别命名实体,然后采用聚类算法对识别出的实体对象进行聚类。先从少量实例中自动发现具有区分力的模式,进而扩展到海量文本范围的分类聚类。
Whitelaw等提出根据已知实体实例进行特征建模,利用模型从海量数据集中得到新的命名实体列表,然后再针对新实体建模,迭代地生成实体标注语料库。
**关系抽取**
经过实体抽取, 知识库目前得到的仅是一系列离散的命名实体,。为了得到更准确的语义信息, 还需要从文本语料中提取出实体之间的关联关系, 以此形成网状的知识结构,这种技术则为关系抽取技术。
- 基于模板的方法
- 基于机器学习的方法
- 开放式实体关系抽取(OIE):
- 二元开放式关系抽取:两个实体之间的关系。*有:KnowItAll、TextRunner、WOE(OIE一代)、OIE ReVerb(OIE二代)、OLLIE(OIE三代)*
- n元开放式关系抽取:实体(可能涉及多个)与它的属性的关系。*有:KPAKEN*
- 基于联合推理的实体关系抽取:将实体识别和关系分类两个任务联合起来进行,一个典型的方法是马尔科夫逻辑网(MLN)。*另外还有:StatSnowball、EntSum、Markov逻辑TML*
**属性抽取**
属性抽取是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物, 可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从各个数据源中汇集属性信息,更完整地表述实体属性。
属性的抽取实际上已经包含在关系抽取中了,所以可以将实体属性抽取转化为关系抽取。
- 基于规则与启发式算法的属性抽取方法
- 基于结构化数据训练模型的属性抽取方法:将结构化数据作为可用于属性抽取的训练集,将模型应用于开放域的实体属性抽取
- 基于属性关系模式的属性抽取方法:根据实体属性与属性值之间的关系模式,直接从开放域数据集上抽取属性
**事件抽取**
语义解析
1. 语义搜索
准确地捕捉到用户输入语句后真正的意图,并以此来进行搜索。
2. 知识问答

### 知识表示
**分布式表示**:用一个综合的向量来表示实体对象的语义信息
向量的表示形式使得实体可以被数学方法进行语义相似度计算
分布式表示模型可以对两个实体之间的关系进行预测,也叫做知识图谱的**补全**
**代表模型**
| 模型名 | 思想 | 优缺点 |
| ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 距离模型 | 向量表示实体,实体通过关系矩阵投影到向量空间,计算投影向量之间的距离进行判断 | 由于距离模型中的关系矩阵是两个不同的矩阵,故实体间的协同性较差 |
| 单层神经网络模型 | 在距离模型的基础上加入非线性映射 | 进一步刻画语义相关性,但开销大 |
| 双线性模型(隐变量模型) | 基于实体间关系的双线性变换来刻画实体在关系下的语义相关性 | 简单易于计算,可以表示实体间协同性 |
| 神经张量模型 | 构建实体的向量表示时,将该实体中的所有单词的向量取平均值 | 可重复使用向量构建实体,利于增强低维向量的稠密程度以及实体与关系的语义计算 |
| 矩阵分解模型 | 矩阵分解的方式可得到低维的向量表示 | |
| 翻译模型 | 将知识库中实体之间的关系看成是从实体间的某种平移,并用向量表示 | 参数较少,计算的复杂度显著降低 |
模型为知识库中每个三元组$(h,r,t)$提供了评价函数
单层神经网络模型的非线性模型的评价函数:$f_r(h,t)=\mu_{t}^{T}g(M_{r,l}l_h+M_{r,2}l_t)$
双线性模型的评价函数: $f_r(h,t)=l_{h}^TM_rl_t$
$M_r\in \R^{d\times d}$是通过关系$r$定义的双线性变换矩阵;$l_h,l_t\in \R^d$是三元组中头实体和尾实体的向量化表示。
神经张量模型的评价函数: $f_r{h,t}=\mu_{r}^{T}g(l_hM_Rl_t+M_{r,l}l_h+M_{r,2}l_t+b_r)$
```
$\mu_r^T\in \R^k$是r的向量化表示
$g(\cdot)$是tanh函数
$M_r\in \R^{d\times d\times k}$是一个三阶张量
$M_{r,l},M_{r,2}\in \R^{d\times k}$是通过关系$r$定义到两个投影矩阵
```
矩阵模型:
知识库中的三元组$(h,r,t)$集合被表示为一个三阶张量,如果该三元组存在,张量中对应位置元素被置1,否则为0。
通过张量分解算法,可将张连长每个三元组${h,r,t}$对应的张量值分解成双线性模型中的知识表示形式$f_r(h,t)$并且使得$|X_hrt-l_h^TM_rl_t|_{L_2}$最小
翻译模型:对每个三元组 都希望满足$l_h+l_r\approx l_t$ ,其损失函数为: $f_r(h,t)=|l_h+l_r-l_t|_{L_1/L_2}$
**复杂关系模型**
知 识 库 中 的 实 体 关 系 类 型 也 可 分 为 1-to-1 、 1-to-N、N-to-1、N-to-N4种类型,而复杂关系主要 指的是1-to-N、N-to-1、N-to-N的3种关系类型.
由于TransE模型无法用于处理复杂模型,于是推出了一系列基于TransE的扩展模型
- *TransE模型无法处理:
1:n、n:1、n:m的情况,这些情况在嵌入空间中难以简单的通过向量加法来表示
具有层次结构或复杂逻辑的复合关系
属性和量化关系,有一些量化的,例如大于这种关系就需要比较,而不是加法*
- *仍基于TransE进行扩展的原因:
计算复杂度低
效率高,适合大规模知识图谱嵌入
灵活扩展,可以引入映射矩阵、复数向量等数学机制
社区支持,大家用TransE还是比较多*
| 模型名 | 特点 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| [TransH](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=TransH&zhida_source=entity) | 引入超平面 |
| [TransR](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=TransR&zhida_source=entity) | 为每一个关系学习一个映射矩阵,使实体和关系存在于不同空间中 |
| [TransD](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=TransD&zhida_source=entity) | 为实体和关系分别学习表示向量和映射向量 |
| TransG | 提出了一种图结构来表示实体和关系,其中每个实体或关系可以由多个节点组成的图来表示 |
| [KG2E](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=KG2E&zhida_source=entity) | 使用高斯分布的均值表示实体或关系在语义空间中的中心位置,协方差则表示实体或关系的不确定度 |
### 知识融合
通过知识抽取的结果可能存在大量冗余和错误信息,形成的结构化信息也会缺乏层次性和逻辑性,因此需要对抽取来的信息做知识融合,消除歧义概念、剔除冗余和错误概念,提升知识质量。
知识融合分为实体链接和知识合并两部分。实体链接(entity linking)指将在文本中抽取出来的实体链接到知识库中正确实体。知识合并指从第三方知识库产品或已有数据化数据中获取知识输入,包括合并外部知识库和合并关系数据库。
比如维基和雅虎对于同一个实体的记录,从而判定这两个记录的实体是相似的。
属性相似度、实体相似度、属性相似度计算方法、实体相似度计算方法。
框架/本体匹配
元素级匹配
- 基于字符串
- 基于语言学,如wordnet
结构级匹配
- 基于图
- 基于分类体系
- 基于统计分析的匹配
实体链接举例

- **实体对齐
**在不同的知识图谱中找出同一个实体,并将这些实体进行对齐(合并、关联)。必然涉及到实体相似度的计算
- 在进行实体对齐时有以下挑战:
- **计算复杂度**会随着知识库的规模呈二次增长
- **数据质量**在不同的知识库中良莠不齐,存在相似重复、孤立等问题
- **先验训练数据**获取困难,通常需要手工构造
- 实体对齐的主要流程包括:
- 进行**分区索引**,以降低计算复杂度
- 利用相似度函数或算法**查找匹配的实例**
- 利用实体对齐算法进行**实例融合**
- **合并**查找和融合的结果,形成最终结果
- 实体对齐可分为两大类:
- 成对实体对齐
- 基于传统概率模型的实体对齐方法:考虑两个实体各自属性的相似性,而不考虑关系
- 基于机器学习的实体对齐方法:将实体对齐问题转化为二分类(对齐类、非对齐类)问题
- 集体实体对齐
- 局部集体实体对齐方法:为实体的属性设置不同的权重,以此计算不同实体的总体相似度
- 全局集体实体对齐方法
- 基于相似性传播的集体实体对齐方法:与已匹配的两个实体直接关联的两个实体也会具有较高的相似性
- 基于概率模型的集体实体对齐方法:采用统计关系学习进行计算与推理以得出可能的对齐实体
- 协同实体对齐
- 协调不同对象间的匹配情况
- 基于表示学习
- 将多个知识库
### 知识加工
通过知识抽取、知识融合得到一系列的基本事实表达,离结构化、网络化的知识体系仍有一段距离。因此还需要针对这些事实表达进行知识加工,包括本体构建、知识推理和质量评估。
- **本体构建**:本体一个树状结构,具有严格的IsA关系,有利于约束推理.本体构建(ontology)指对概念建模的规范,以形式化方式明确定义概念之间的联系。在知识图谱中,本体位于模式层,用于描述概念层次体系的知识概念模版。
自动构建过程可以分为3个阶段:
- 纵向概念间的并列关系计算:计算两个纵向实体(例如:动物和猫)间的并列关系的相似度,以判断它们是否在语义层面属于同一概念(一族)
- 实体上下位的关系抽取:提取两个纵向实体之间的关系(猫*是一种*动物)
- 本体生成:对各层得到的概念进行聚类,并为每一类的实体指定公共上位词
- **质量评估:**评估通常与实体对齐任务一同进行。量化可信度,保留置信度高的,舍弃置信度低的
### 知识更新
### 知识推理
知识推理指从知识库中已有的实体关系数据经过计算建立新实体关联,从现有知识中发现新知识,拓展和丰富知识网络。例如已知 (乾隆, 父亲, 雍正) 和 (雍正, 父亲, 康熙) , 可以得到 (乾隆, 祖父, 康熙) 或 (康熙, 孙子, 乾隆) 。知识推理的对象除了实体关系,还包括实体的属性值、本体概念层次关系等。例如已知 (老虎, 科, 猫科) 和 (猫科, 目, 食肉目) , 可以推出 (老虎, 目, 食肉目) 。
知识推理可以分为**基于逻辑**的推理和**基于图**的推理
- 基于逻辑的推理
- 一阶谓词逻辑: :$\forall x(Human(x) \rightarrow Kill(x))$:对于所有的x,如果x是人,则x是可杀死的
- 描述逻辑: :$Teacher(x) : - Professor(x)$:如果x是教授,则x是老师
- 基于图的推理
在图中进行一些比如限制路径的随机游走、路径排序等算法,重在挖掘关系路径中隐含的信息
## 问题与挑战
### 知识抽取不够准确
受到算法准召率低、限制条件多、扩展性不好等问题,针对开放域的信息抽取仍面对很大挑战。
### 知识融合实体链接不够准确
实体消歧、合并外部数据库和关系数据库的应用效果仍有很大提升空间。大规模知识库的融合(并行、分布式、众包算法(众包算法可以提高知识融合的质量))
### 知识加工技术难
本体构建中的聚类问题、质量评估的标准和指标的建立和知识推理的技术思维限制,都是知识加工的重要难点。
### 知识表示
对认知科学的研究总是有助于知识表示的优化
### 跨语言知识库对齐
### 知识图谱的应用
传统的互联网,基于关键词字符串匹配.
1. 爬取网页建立倒排索引
2. 基于倒排索引搜索引擎首先找到了包含关键词的网页
3. 根据打分策略(PageRank,HITS等),对网页排序,返回给用户
计算机并不识别背后的语义。构建知识图谱的目的就是让机器具备认知能力。每个研究者都从它之前的研究背景出发研究知识图谱。
1. 数据库,RDF数据库系统,数据集成,知识融合
2. 机器学习,知识图谱数据的知识表示。(图嵌入)
3. 知识工程 ,知识库构建,基于规则的推理。知识工程的核心:知识库和推理引擎。
领域本体的构建:面向特定领域的形式化地对于共享概念体系的明确而又详细的说明。
知识抽取
知识融合
4. 自然语言处理,信息抽取,语义解析
自然语言处理为知识图谱抽取知识
知识图谱为自然语言处理提升NLP任务的准确度。
信息抽取:实体识别与抽取、实体消歧、关系抽取
语义解析:词义消岐、语义角色标注、指代消解。
## 图数据库
### 大规模知识库
1. 开放链接知识库
它们中不仅包含大量的半结构化、非结构 化数据,是知识图谱数据的重要来源。而且具有较 高的领域覆盖面,与领域知识库存在大量的链接关 系。
2. 垂直行业知识库
这类知识 库的描述目标是特定的行业领域,通常需要依靠特 定行业的数据才能构建,因此其描述范围极为有限。
## 关键技术
### 本体
计算机科学中,“本体”用于面对特定领域的形式化地对于共享概念体系的明确而又详细的说明。
是一种概念间的关系和相互间的规则。
比如“疾病”,在医学中的疾病本体,疾病中包含药物、科室、感染类疾病、传染类疾病
本体语言
DAML/W3C提出的DAML+OIL3以及知识图谱数据集常用W3C所定义的RDF(S)和OWL语言等。
工具
Protege和WebOnto
实体识别
实体消歧
关系抽取
事件抽取
### 知识抽取
知识抽取(information extraction)是构建知识图谱的第一步,为了从异构数据源中获取候选知识单元,知识抽取技术将自动从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息。
- 结构化数据
- 半结构化数据
- 非结构文本数据
一些长尾(long-tail)的数据就得要从文本数据
大规模知识抽取——全领域、开放领域,主要用于互联网公司的搜索引擎
Yago
DBPedia
Freebase:人们编辑结构化知识
**实体抽取**
实体抽取,也称为命名实体识别(named entity recognition,NER),指从源数据中自动识别命名实体,这一步是信息抽取中最基础和关键的部分,因为实体抽取的准确率和召回率对后续知识获取效率和质量影响很大。
- 基于规则与词典的方法:在有限的范围内,依靠大量专家编写规则,抽取信息
- 基于统计机器学习的方法:将机器学习中的监督学习算法用于抽取信息,单纯的监督学习性能、准确率都不够理想。
- 利用预先标注好的语料训练模型
最大熵膜学和条件随机模型。采用字典辅助下的最大熵算法,基于Medline论文摘要的GENIA数据集使得实体抽取的准召率均超过70%。
- 面向开放域的无监督学习算法,事先不给实体分类,而是基于实体的语义特征从搜索日志中识别命名实体,然后采用聚类算法对识别出的实体对象进行聚类。先从少量实例中自动发现具有区分力的模式,进而扩展到海量文本范围的分类聚类。
Whitelaw等提出根据已知实体实例进行特征建模,利用模型从海量数据集中得到新的命名实体列表,然后再针对新实体建模,迭代地生成实体标注语料库。
**关系抽取**
经过实体抽取, 知识库目前得到的仅是一系列离散的命名实体,。为了得到更准确的语义信息, 还需要从文本语料中提取出实体之间的关联关系, 以此形成网状的知识结构,这种技术则为关系抽取技术。
- 基于模板的方法
- 基于机器学习的方法
- 开放式实体关系抽取(OIE):
- 二元开放式关系抽取:两个实体之间的关系。*有:KnowItAll、TextRunner、WOE(OIE一代)、OIE ReVerb(OIE二代)、OLLIE(OIE三代)*
- n元开放式关系抽取:实体(可能涉及多个)与它的属性的关系。*有:KPAKEN*
- 基于联合推理的实体关系抽取:将实体识别和关系分类两个任务联合起来进行,一个典型的方法是马尔科夫逻辑网(MLN)。*另外还有:StatSnowball、EntSum、Markov逻辑TML*
**属性抽取**
属性抽取是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物, 可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从各个数据源中汇集属性信息,更完整地表述实体属性。
属性的抽取实际上已经包含在关系抽取中了,所以可以将实体属性抽取转化为关系抽取。
- 基于规则与启发式算法的属性抽取方法
- 基于结构化数据训练模型的属性抽取方法:将结构化数据作为可用于属性抽取的训练集,将模型应用于开放域的实体属性抽取
- 基于属性关系模式的属性抽取方法:根据实体属性与属性值之间的关系模式,直接从开放域数据集上抽取属性
**事件抽取**
语义解析
1. 语义搜索
准确地捕捉到用户输入语句后真正的意图,并以此来进行搜索。
2. 知识问答

### 知识表示
**分布式表示**:用一个综合的向量来表示实体对象的语义信息
向量的表示形式使得实体可以被数学方法进行语义相似度计算
分布式表示模型可以对两个实体之间的关系进行预测,也叫做知识图谱的**补全**
**代表模型**
| 模型名 | 思想 | 优缺点 |
| ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 距离模型 | 向量表示实体,实体通过关系矩阵投影到向量空间,计算投影向量之间的距离进行判断 | 由于距离模型中的关系矩阵是两个不同的矩阵,故实体间的协同性较差 |
| 单层神经网络模型 | 在距离模型的基础上加入非线性映射 | 进一步刻画语义相关性,但开销大 |
| 双线性模型(隐变量模型) | 基于实体间关系的双线性变换来刻画实体在关系下的语义相关性 | 简单易于计算,可以表示实体间协同性 |
| 神经张量模型 | 构建实体的向量表示时,将该实体中的所有单词的向量取平均值 | 可重复使用向量构建实体,利于增强低维向量的稠密程度以及实体与关系的语义计算 |
| 矩阵分解模型 | 矩阵分解的方式可得到低维的向量表示 | |
| 翻译模型 | 将知识库中实体之间的关系看成是从实体间的某种平移,并用向量表示 | 参数较少,计算的复杂度显著降低 |
模型为知识库中每个三元组$(h,r,t)$提供了评价函数
单层神经网络模型的非线性模型的评价函数:$f_r(h,t)=\mu_{t}^{T}g(M_{r,l}l_h+M_{r,2}l_t)$
双线性模型的评价函数: $f_r(h,t)=l_{h}^TM_rl_t$
$M_r\in \R^{d\times d}$是通过关系$r$定义的双线性变换矩阵;$l_h,l_t\in \R^d$是三元组中头实体和尾实体的向量化表示。
神经张量模型的评价函数: $f_r{h,t}=\mu_{r}^{T}g(l_hM_Rl_t+M_{r,l}l_h+M_{r,2}l_t+b_r)$
```
$\mu_r^T\in \R^k$是r的向量化表示
$g(\cdot)$是tanh函数
$M_r\in \R^{d\times d\times k}$是一个三阶张量
$M_{r,l},M_{r,2}\in \R^{d\times k}$是通过关系$r$定义到两个投影矩阵
```
矩阵模型:
知识库中的三元组$(h,r,t)$集合被表示为一个三阶张量,如果该三元组存在,张量中对应位置元素被置1,否则为0。
通过张量分解算法,可将张连长每个三元组${h,r,t}$对应的张量值分解成双线性模型中的知识表示形式$f_r(h,t)$并且使得$|X_hrt-l_h^TM_rl_t|_{L_2}$最小
翻译模型:对每个三元组 都希望满足$l_h+l_r\approx l_t$ ,其损失函数为: $f_r(h,t)=|l_h+l_r-l_t|_{L_1/L_2}$
**复杂关系模型**
知 识 库 中 的 实 体 关 系 类 型 也 可 分 为 1-to-1 、 1-to-N、N-to-1、N-to-N4种类型,而复杂关系主要 指的是1-to-N、N-to-1、N-to-N的3种关系类型.
由于TransE模型无法用于处理复杂模型,于是推出了一系列基于TransE的扩展模型
- *TransE模型无法处理:
1:n、n:1、n:m的情况,这些情况在嵌入空间中难以简单的通过向量加法来表示
具有层次结构或复杂逻辑的复合关系
属性和量化关系,有一些量化的,例如大于这种关系就需要比较,而不是加法*
- *仍基于TransE进行扩展的原因:
计算复杂度低
效率高,适合大规模知识图谱嵌入
灵活扩展,可以引入映射矩阵、复数向量等数学机制
社区支持,大家用TransE还是比较多*
| 模型名 | 特点 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| [TransH](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=TransH&zhida_source=entity) | 引入超平面 |
| [TransR](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=TransR&zhida_source=entity) | 为每一个关系学习一个映射矩阵,使实体和关系存在于不同空间中 |
| [TransD](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=TransD&zhida_source=entity) | 为实体和关系分别学习表示向量和映射向量 |
| TransG | 提出了一种图结构来表示实体和关系,其中每个实体或关系可以由多个节点组成的图来表示 |
| [KG2E](https://zhida.zhihu.com/search?content_id=248264413&content_type=Article&match_order=1&q=KG2E&zhida_source=entity) | 使用高斯分布的均值表示实体或关系在语义空间中的中心位置,协方差则表示实体或关系的不确定度 |
### 知识融合
通过知识抽取的结果可能存在大量冗余和错误信息,形成的结构化信息也会缺乏层次性和逻辑性,因此需要对抽取来的信息做知识融合,消除歧义概念、剔除冗余和错误概念,提升知识质量。
知识融合分为实体链接和知识合并两部分。实体链接(entity linking)指将在文本中抽取出来的实体链接到知识库中正确实体。知识合并指从第三方知识库产品或已有数据化数据中获取知识输入,包括合并外部知识库和合并关系数据库。
比如维基和雅虎对于同一个实体的记录,从而判定这两个记录的实体是相似的。
属性相似度、实体相似度、属性相似度计算方法、实体相似度计算方法。
框架/本体匹配
元素级匹配
- 基于字符串
- 基于语言学,如wordnet
结构级匹配
- 基于图
- 基于分类体系
- 基于统计分析的匹配
实体链接举例

- **实体对齐
**在不同的知识图谱中找出同一个实体,并将这些实体进行对齐(合并、关联)。必然涉及到实体相似度的计算
- 在进行实体对齐时有以下挑战:
- **计算复杂度**会随着知识库的规模呈二次增长
- **数据质量**在不同的知识库中良莠不齐,存在相似重复、孤立等问题
- **先验训练数据**获取困难,通常需要手工构造
- 实体对齐的主要流程包括:
- 进行**分区索引**,以降低计算复杂度
- 利用相似度函数或算法**查找匹配的实例**
- 利用实体对齐算法进行**实例融合**
- **合并**查找和融合的结果,形成最终结果
- 实体对齐可分为两大类:
- 成对实体对齐
- 基于传统概率模型的实体对齐方法:考虑两个实体各自属性的相似性,而不考虑关系
- 基于机器学习的实体对齐方法:将实体对齐问题转化为二分类(对齐类、非对齐类)问题
- 集体实体对齐
- 局部集体实体对齐方法:为实体的属性设置不同的权重,以此计算不同实体的总体相似度
- 全局集体实体对齐方法
- 基于相似性传播的集体实体对齐方法:与已匹配的两个实体直接关联的两个实体也会具有较高的相似性
- 基于概率模型的集体实体对齐方法:采用统计关系学习进行计算与推理以得出可能的对齐实体
- 协同实体对齐
- 协调不同对象间的匹配情况
- 基于表示学习
- 将多个知识库
### 知识加工
通过知识抽取、知识融合得到一系列的基本事实表达,离结构化、网络化的知识体系仍有一段距离。因此还需要针对这些事实表达进行知识加工,包括本体构建、知识推理和质量评估。
- **本体构建**:本体一个树状结构,具有严格的IsA关系,有利于约束推理.本体构建(ontology)指对概念建模的规范,以形式化方式明确定义概念之间的联系。在知识图谱中,本体位于模式层,用于描述概念层次体系的知识概念模版。
自动构建过程可以分为3个阶段:
- 纵向概念间的并列关系计算:计算两个纵向实体(例如:动物和猫)间的并列关系的相似度,以判断它们是否在语义层面属于同一概念(一族)
- 实体上下位的关系抽取:提取两个纵向实体之间的关系(猫*是一种*动物)
- 本体生成:对各层得到的概念进行聚类,并为每一类的实体指定公共上位词
- **质量评估:**评估通常与实体对齐任务一同进行。量化可信度,保留置信度高的,舍弃置信度低的
### 知识更新
### 知识推理
知识推理指从知识库中已有的实体关系数据经过计算建立新实体关联,从现有知识中发现新知识,拓展和丰富知识网络。例如已知 (乾隆, 父亲, 雍正) 和 (雍正, 父亲, 康熙) , 可以得到 (乾隆, 祖父, 康熙) 或 (康熙, 孙子, 乾隆) 。知识推理的对象除了实体关系,还包括实体的属性值、本体概念层次关系等。例如已知 (老虎, 科, 猫科) 和 (猫科, 目, 食肉目) , 可以推出 (老虎, 目, 食肉目) 。
知识推理可以分为**基于逻辑**的推理和**基于图**的推理
- 基于逻辑的推理
- 一阶谓词逻辑: :$\forall x(Human(x) \rightarrow Kill(x))$:对于所有的x,如果x是人,则x是可杀死的
- 描述逻辑: :$Teacher(x) : - Professor(x)$:如果x是教授,则x是老师
- 基于图的推理
在图中进行一些比如限制路径的随机游走、路径排序等算法,重在挖掘关系路径中隐含的信息
## 问题与挑战
### 知识抽取不够准确
受到算法准召率低、限制条件多、扩展性不好等问题,针对开放域的信息抽取仍面对很大挑战。
### 知识融合实体链接不够准确
实体消歧、合并外部数据库和关系数据库的应用效果仍有很大提升空间。大规模知识库的融合(并行、分布式、众包算法(众包算法可以提高知识融合的质量))
### 知识加工技术难
本体构建中的聚类问题、质量评估的标准和指标的建立和知识推理的技术思维限制,都是知识加工的重要难点。
### 知识表示
对认知科学的研究总是有助于知识表示的优化
### 跨语言知识库对齐
### 知识图谱的应用
传统的互联网,基于关键词字符串匹配.
1. 爬取网页建立倒排索引
2. 基于倒排索引搜索引擎首先找到了包含关键词的网页
3. 根据打分策略(PageRank,HITS等),对网页排序,返回给用户
计算机并不识别背后的语义。构建知识图谱的目的就是让机器具备认知能力。每个研究者都从它之前的研究背景出发研究知识图谱。
1. 数据库,RDF数据库系统,数据集成,知识融合
2. 机器学习,知识图谱数据的知识表示。(图嵌入)
3. 知识工程 ,知识库构建,基于规则的推理。知识工程的核心:知识库和推理引擎。
领域本体的构建:面向特定领域的形式化地对于共享概念体系的明确而又详细的说明。
知识抽取
知识融合
4. 自然语言处理,信息抽取,语义解析
自然语言处理为知识图谱抽取知识
知识图谱为自然语言处理提升NLP任务的准确度。
信息抽取:实体识别与抽取、实体消歧、关系抽取
语义解析:词义消岐、语义角色标注、指代消解。
## 图数据库
 ### 图数据库的定义
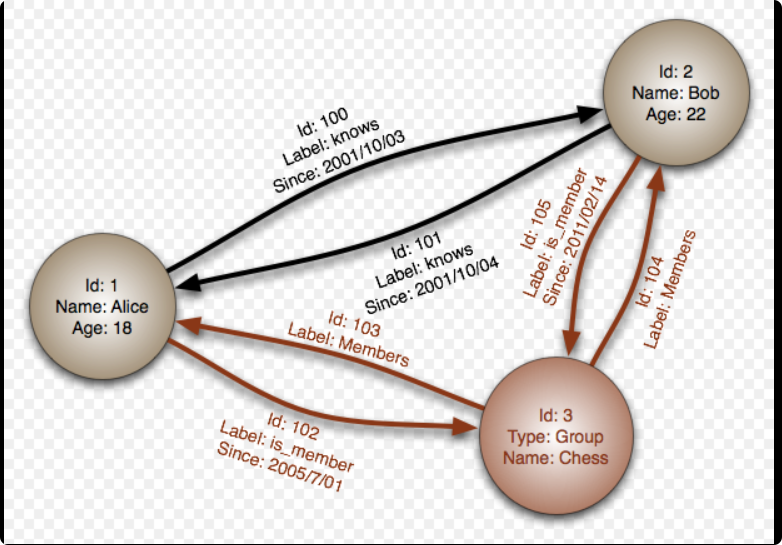
**图数据库**(graph database,**GDB**)是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。
该系统的关键概念是**图**,它直接将存储中的数据项,与数据**节点**和节点间表示关系的**边**的集合相关联。
这些关系允许直接将存储区中的数据链接在一起,并且在许多情况下,可以通过一个操作进行检索。
图数据库将数据之间的关系作为优先级。查询图数据库中的关系很快,因为它们永久存储在数据库本身中。可以使用图数据库直观地显示关系,使其对于高度互连的数据非常有用。
### 从关系型数据库到非关系型数据库
图数据库是一种非关系型数据库。图模型明确地列出了数据节点之间的依赖关系,而关系模型和其他NoSQL数据库模型则通过隐式连接来链接数据。图数据库从设计上,就是可以简单快速地检索难以在关系系统中建模的复杂层次结构的。图数据库与20世纪70年代的网络模型数据库相似,它们都表示一般的图,但是网络模型数据库在较低的抽象层次上运行,并且不能轻松遍历一系列边。
图数据库的底层存储机制可能各有不同。有些依赖于关系引擎并将图数据“存储”到表中(虽然表是一个逻辑元素,但是这种方法在图数据库、图数据库管理系统和实际存储数据的物理设备之间施加了另一层抽象)。另一些则使用键值存储或面向文档的数据库进行存储,使它们具有固有的NoSQL结构。大多数基于非关系存储引擎的图数据库还添加了**标记**或**属性**的概念,这些标记或属性本质上是具有指向另一个文档的指针的关系。这样就可以对数据元素进行分类,以便于集中检索。
从图数据库中检索数据需要SQL之外的查询语言,SQL是为了处理关系系统中的数据而设计的,因此无法“优雅地”处理遍历图。截至2017年,没有一个像SQL那样通用的图查询语言,通常都是仅限与一个产品的。不过,已经有一些标准化的工作,使得Gremlin、SPARQL和Cypher成为了多供应商查询语言。除了具有查询语言接口外,还可以通过应用程序接口(API)访问一些图数据库。
### 图数据库的定义
**图数据库**(graph database,**GDB**)是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。
该系统的关键概念是**图**,它直接将存储中的数据项,与数据**节点**和节点间表示关系的**边**的集合相关联。
这些关系允许直接将存储区中的数据链接在一起,并且在许多情况下,可以通过一个操作进行检索。
图数据库将数据之间的关系作为优先级。查询图数据库中的关系很快,因为它们永久存储在数据库本身中。可以使用图数据库直观地显示关系,使其对于高度互连的数据非常有用。
### 从关系型数据库到非关系型数据库
图数据库是一种非关系型数据库。图模型明确地列出了数据节点之间的依赖关系,而关系模型和其他NoSQL数据库模型则通过隐式连接来链接数据。图数据库从设计上,就是可以简单快速地检索难以在关系系统中建模的复杂层次结构的。图数据库与20世纪70年代的网络模型数据库相似,它们都表示一般的图,但是网络模型数据库在较低的抽象层次上运行,并且不能轻松遍历一系列边。
图数据库的底层存储机制可能各有不同。有些依赖于关系引擎并将图数据“存储”到表中(虽然表是一个逻辑元素,但是这种方法在图数据库、图数据库管理系统和实际存储数据的物理设备之间施加了另一层抽象)。另一些则使用键值存储或面向文档的数据库进行存储,使它们具有固有的NoSQL结构。大多数基于非关系存储引擎的图数据库还添加了**标记**或**属性**的概念,这些标记或属性本质上是具有指向另一个文档的指针的关系。这样就可以对数据元素进行分类,以便于集中检索。
从图数据库中检索数据需要SQL之外的查询语言,SQL是为了处理关系系统中的数据而设计的,因此无法“优雅地”处理遍历图。截至2017年,没有一个像SQL那样通用的图查询语言,通常都是仅限与一个产品的。不过,已经有一些标准化的工作,使得Gremlin、SPARQL和Cypher成为了多供应商查询语言。除了具有查询语言接口外,还可以通过应用程序接口(API)访问一些图数据库。